継続的可用性概要
はじめに
HA(High Availability=高可用性)は、強化されたアップタイムとスループットを通して、従来の単一サーバーノードより高いレベルの運用パフォーマンスを実現できるように設計されたコンピューターシステムを表すために使用される一般的な用語です。
継続的可用性を備えたTigerGraphは、高可用性の標準的な範囲や定義を超え、以下の機能を提供します。
-
データベースサーバーのロスに対するフォールトトレランス
-
クラスター内障害に対するサービスの自動回復
-
-
ユーザー向けアプリケーションの完全なネイティブHAサポート - 待機GSQLサーバーおよびGraphStudioサーバーへの切れ目のない自動クライアント再接続
-
障害回復中のリモートクラスターへのフェイルオーバー
-
追加のレプリカによりRoIを改善
-
クエリースループットパフォーマンスを強化
-
運用ワークロードの同時実行性を向上
-
つまり、TigerGraphの継続的可用性は、大きなダウンタイムなしにビジネスアプリケーションを実行し続ける機能を提供するだけでなく、投資に対するより高い利益をも実現します。
アーキテクチャーの設計
TigerGraphのアーキテクチャー設計は、アクティブ/アクティブレプリケーションに依存し、複数のデータコピーの同期を維持します。 これはユーザーにとってはトランスペアレントです。 データを均一に分割するという基本的原則は、レプリカがいくつ格納されているかに関わらず、自動的に適用されます。 さらに、レプリカの配置は、インフラストラクチャーに対応しており、ハードウェア障害に耐性を持ちます。 継続的可用性は、お客様がクラスターのインストール時に選択できる設定です。 お客様は、インフラストラクチャーの要件に基づき、レプリカを特定のアベイラビリティーゾーンやデータセンターに置くことができます。
TigerGraphの継続的可用性設計が実現すること
-
スループット: 各レプリカは常に最新の状態を保たれ、読み取り要求の共有を処理します。これによって、クエリーの同時処理性とスループットが向上します。
-
計画的または計画外の理由でサーバーがオフラインになった場合、TigerGraphのHA設計は自動フェイルオーバーを備えているため、運用を維持しつつ、そのサーバーのレプリカノードに作業を再ルーティングします。
-
レプリケーションのレベルが高いほど、スループットと復元力が向上します。
継続的可用性 - 定義
TigerGraphはMPPアーキテクチャーをベースにしています。 すべてのサービスは、クラスター全体に均一に分割されます。 このためには、データをクラスター全体に分割される必要があります。 クラスター設計には、以下に挙げる2つの重要な概念があります。
-
レプリケーションファクター: レプリケーションファクターは、クラスターに格納されるデータのコピーの数を決定するクラスター設計の値です。これは設定可能であり、お客様はインストール時に選択することができます。
-
パーティショニングファクター: パーティショニングファクターは、TigerGraphの内部の値であり、クラスターがデータベース内にいかにデータを分割するかを決定します。クラスターサイズのノードに基づいて、TigerGraphはレプリケーションファクターを考慮してパーティショニングファクターを自動的に選択します。
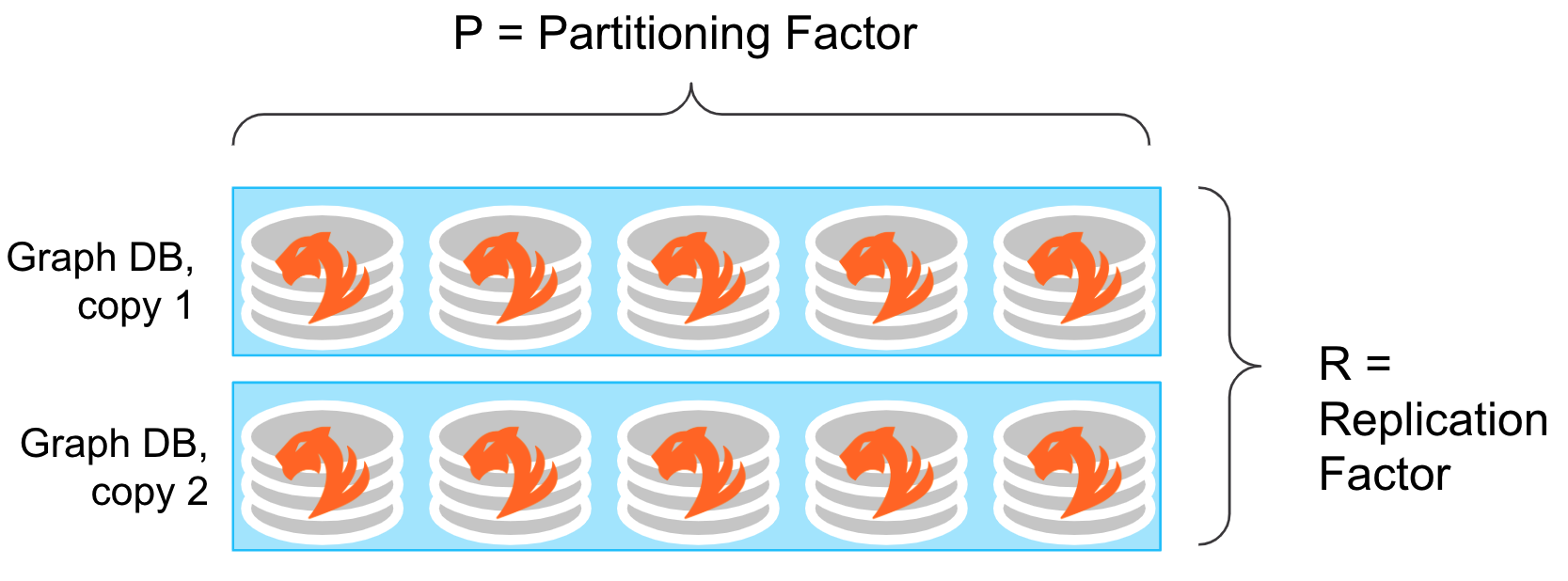
つまり、TigerGraphクラスターは、レプリカの数Rと等しい複数のコピーを持つパーティションPに分割されたデータの組み合わせであると考えることができます。
|
クラスター設計に関する重要考慮事項
|
継続的可用性 - データ処理
TigerGraphサービスは、分割マスターレスアーキテクチャーをベースにしています。すべてのレプリカは同等であり、読み取りおよび書き込み要求の両方に対応できます。 これは、単一のノードが単一障害点になることを防ぐための重要な違いとなります。
-
書き込み処理: すべてのデータセットが完全に整合性を保てるように全レプリカの同期を維持するため、デフォルトでは、書き込み処理はすべてのレプリカに同期的に送信されます。書き込み操作は、すべてのレプリカが書き込みの成功を確認した場合にのみ、完了と見なされます。
-
読み取り処理: すべての書き込み操作において全レプリカの同期が確保されているため、他のレプリカとのデータ整合性の確認を行う必要なしに、どのレプリカにも読み取りリクエストを送信できます。これにより、読み取りを頻繁に行う分析クエリーの読み取りのパフォーマンスが最大限に高まります。
例:
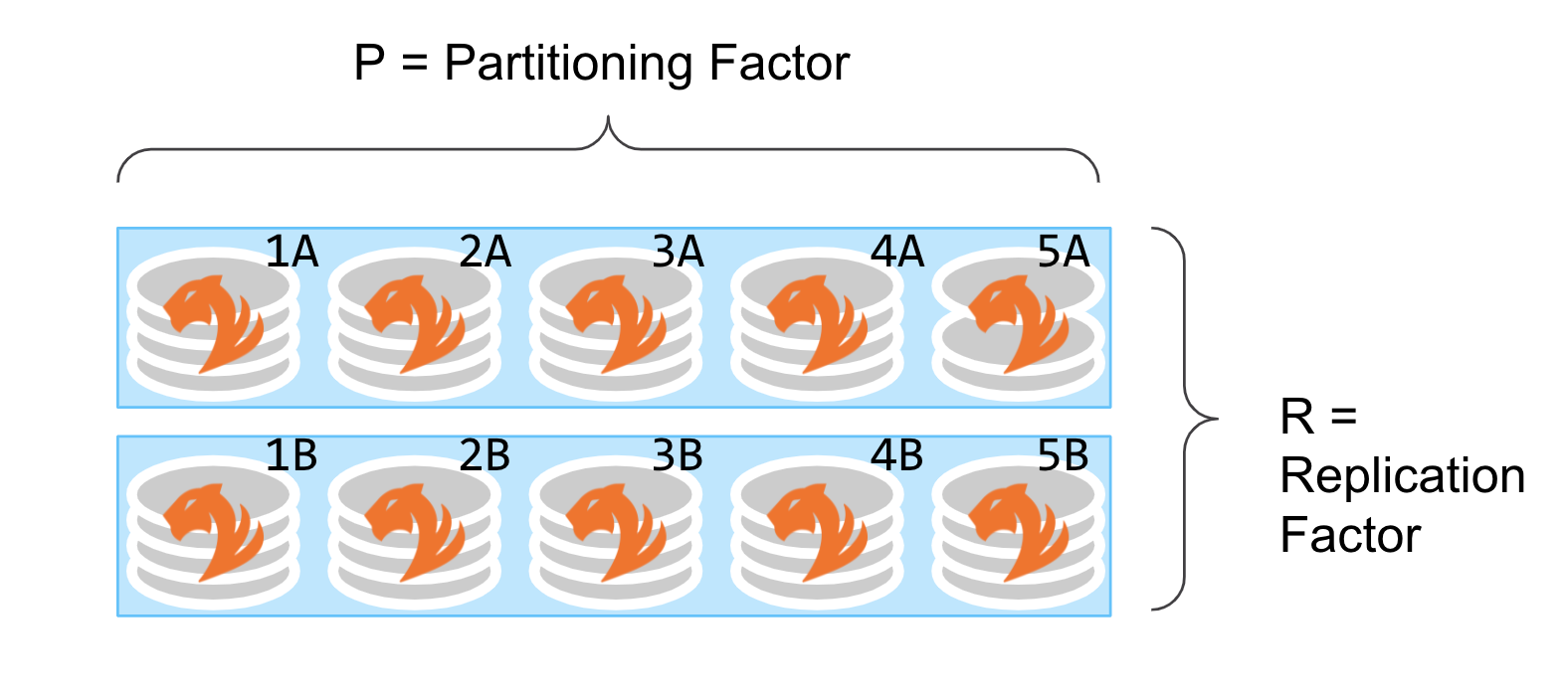
次の例では、クラスター内のデータセットが5つのパーティションに分かれており、データセットのレプリカ2つがあります。つまり、パーティションファクターは5であり、レプリケーションファクターは2です。
-
すべての書き込みは全レプリカ(例: 1Aおよび1Bの両方)に送信されます。
-
読み取りは、いずれか1つのレプリカ(例: 1Aまたは1B)から行うことができます。
-
分割クエリーは、複数のレプリカ(例: {1A、2B、3B、4A、5B})から読み取ることができます。
継続的可用性 - クラスターのフェイルオーバー処理
TigerGraphの設計は、継続的可用性実現のため、自動フェイルオーバーを行うようにしています。サーバーがダウンした(ハードウェアまたはソフトウェア的要因、計画的または計画外)場合でも、着信DB操作を続行できます。 リクエストは、使用できないサーバーを回避して自動的にルーティングされます。 TigerGraphデータベーススケジューラーは、サーバーの可用性をリアルタイムで追跡し、リクエストを適切なサーバーにルーティングします。
![フェイルオーバー例のダイアグラム]](_images/ha-failover.png)
例:
サーバー障害発生時
-
いずれか1台のサーバーが利用できない場合(計画または計画外の理由で)
-
一定回数の試行によって応答を得られなかった場合、リクエストは自動的に別のレプリカに転送されます(例: 3Bが応答不能なため、3Aを使用)
-
トランザクションの途中で障害が発生した場合、そのトランザクションは中止される可能性があります。
-
-
サーバーが復元されるまで、システムは低スループットで作動し続けます。