Spark Connection Via JDBC Driver
Apache Spark is a popular big data distributed processing system which is frequently used in data management ETL process and Machine Learning applications.
Using the open-source type 4 JDBC Driver for TigerGraph, you can read and write data between Spark and TigerGraph. This is a two-way data connection.
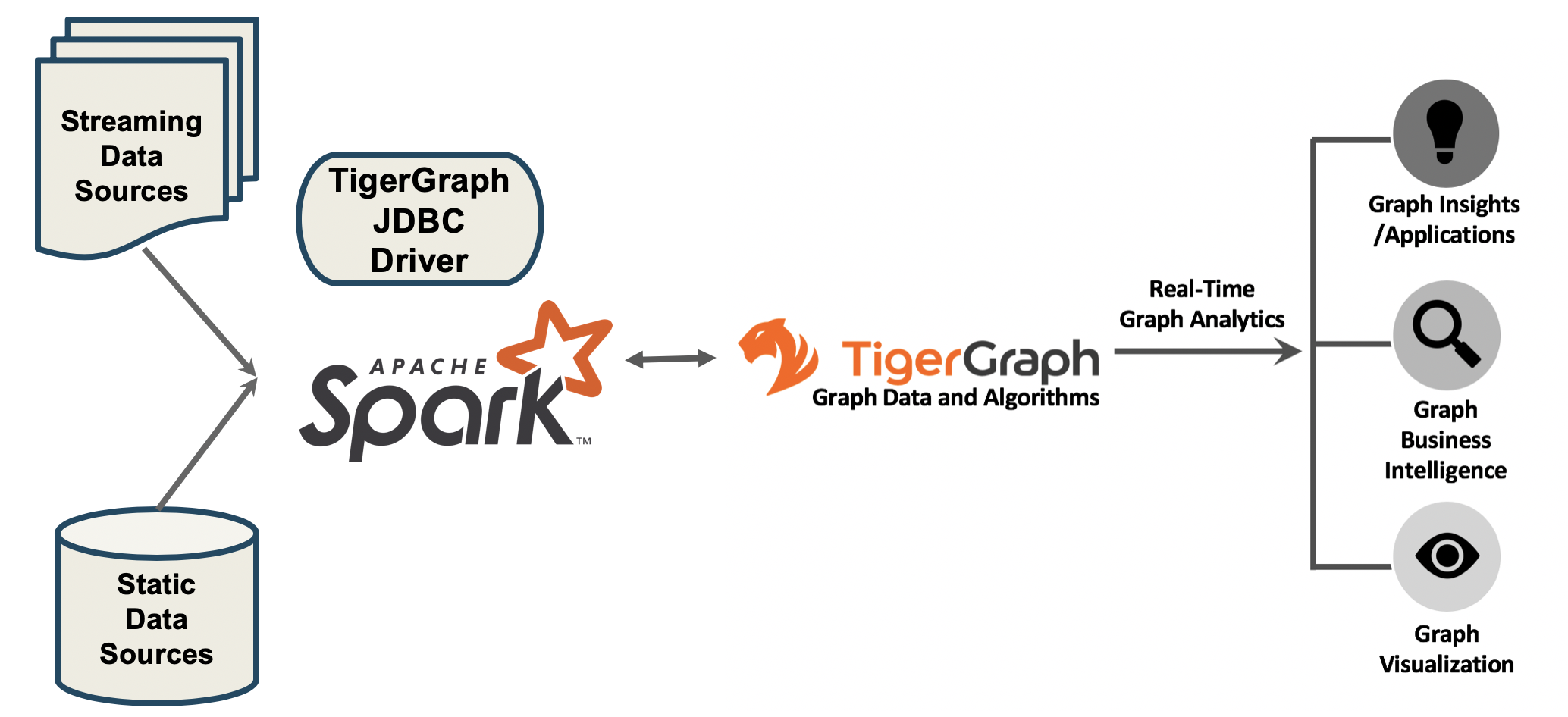
Figure 1. Apache Spark, containing streaming and static data sources, uses the JDBC driver to communicate back and forth with TigerGraph in order to perform graph analytics.
The Github Link to the JDBC Driver is https://github.com/tigergraph/ecosys/tree/master/tools/etl/tg-jdbc-driver
The README file there provides more details.
Note that the TigerGraph JDBC Driver has more use cases than just as a Spark Connection. You can use TigerGraph’s JDBC Driver for your Java and Python applications. This is an open source project.